Using the Coulomb Blockade Models
Installation
We recommend using pip, poetry, or uv to install the package.
Authentication
The SDK requires an API key for authentication. Sign in and create a new API key. Remember, your API key is your access secret—keep it safe with environment variables.
Using environment variables:
Or provide the API key directly:
Usage Examples
Using the Coulomb Blockade Classifier
The Coulomb Blockade Classifier is a model that can classify a given current measurement as either in the Coulomb Blockade regime or not.
You can download an example file to follow along with the example:
Using the Coulomb Blockade Peak Detector
The Coulomb Blockade Peak Detector is a model that can detect the peaks in a given current measurement.
You can download an example file to follow along with the example:
Plotting the Output
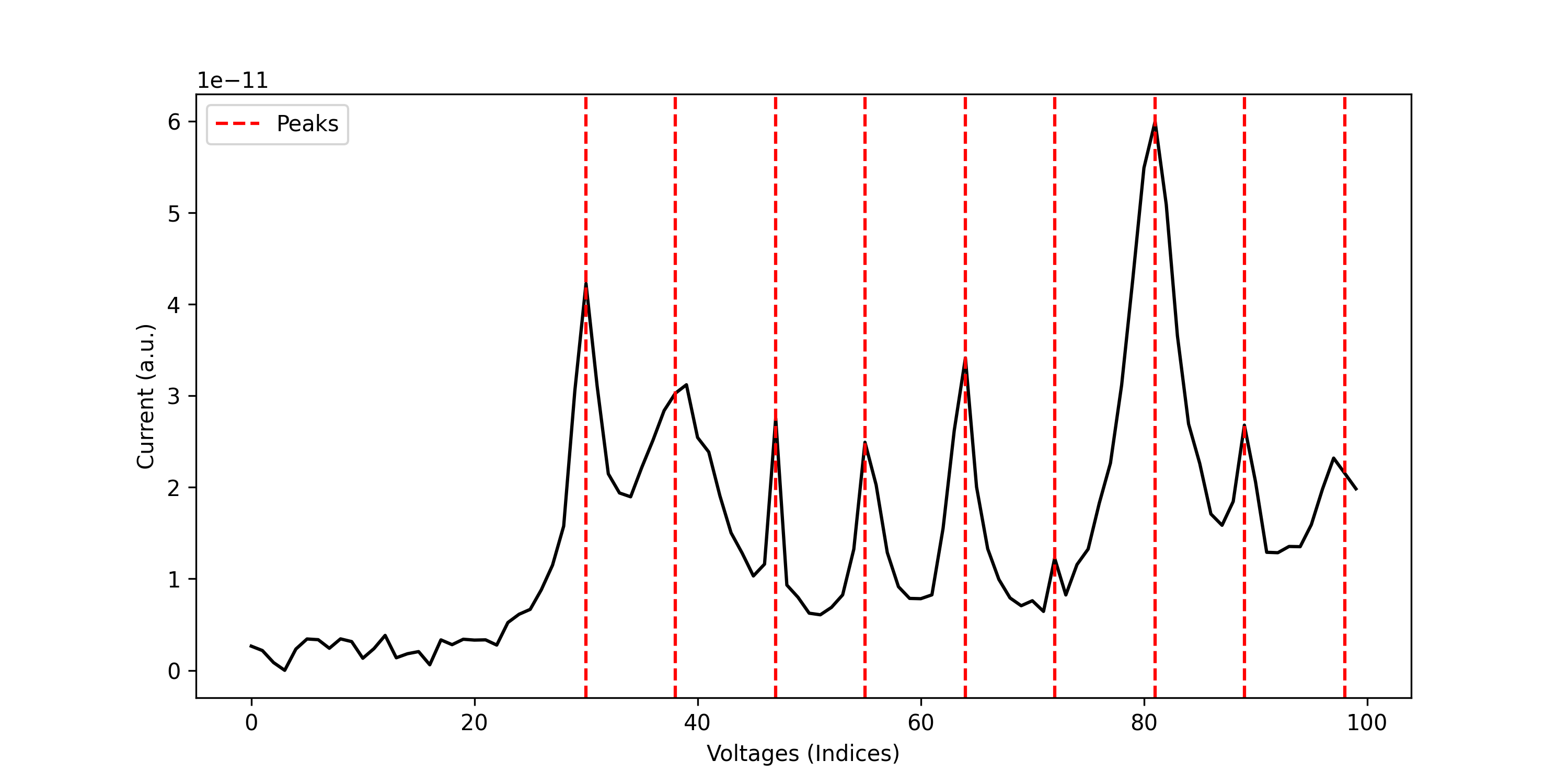
Similarly, for v1 of the Coulomb Blockade Peak Detector, you can download an example file and replace the model name in the example above with coulomb-blockade-peak-detector-v1, and you should see the following output:
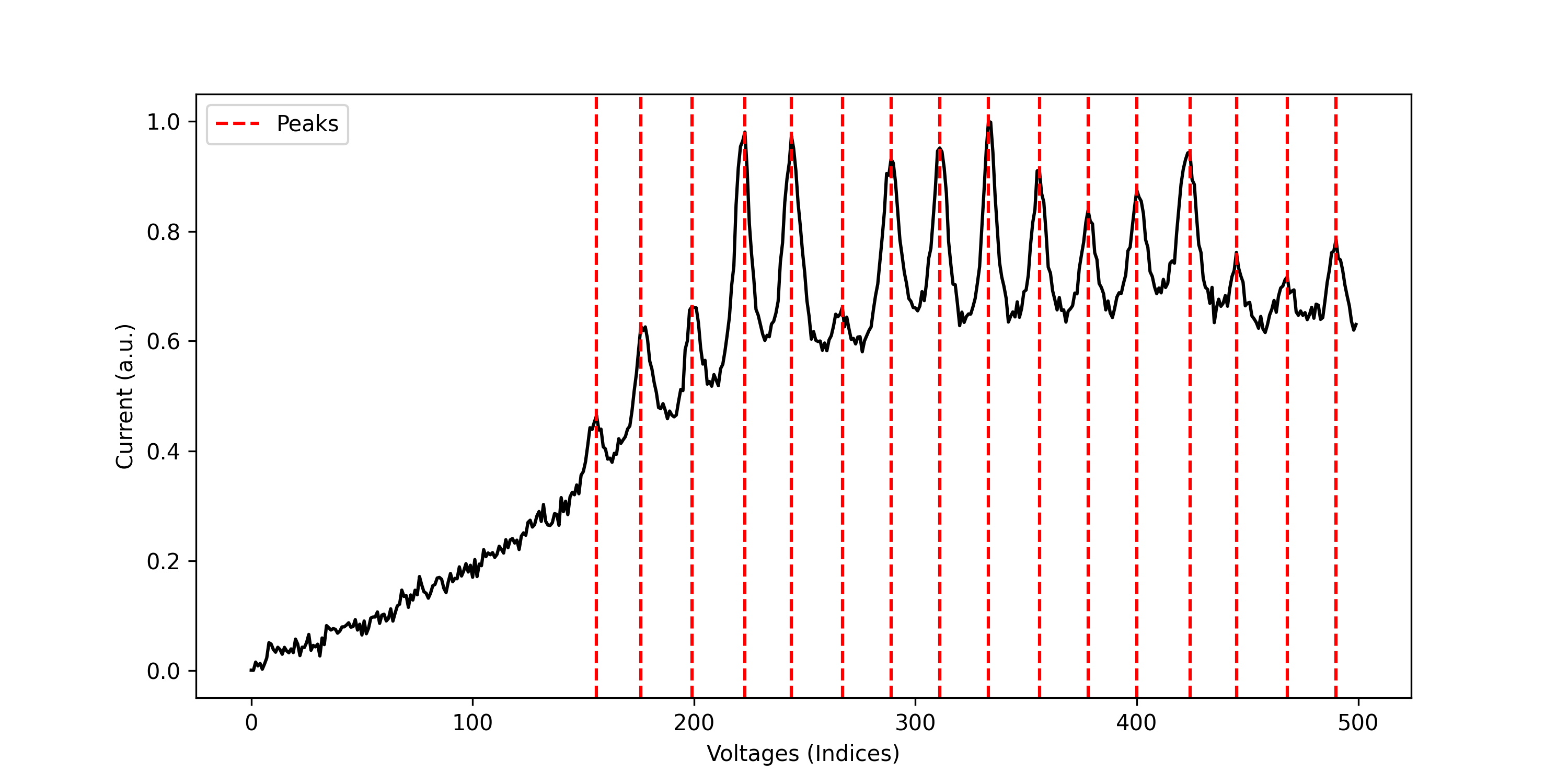
v1 is typically more accurate than v0 for larger sweep sizes of one hundred or more points.
Data Requirements
One-dimensional Current Data
- Shape:
(n, ) - 1D array of current values
Important Notes for Voltage-Current Data
- The array must be of shape (n, ) where n is the number of current values in the measurement.
- Analysis is outputted in terms of indices of the input array.
- The models automatically handle scaling and normalization internally.
- For best results, ensure your data has sufficient resolution in regions of interest.